Related Topics
No topics are associated with this blog
TF-IDF in Python and MySQL
TF-IDF: Term Frequency-Inverse Document Frequency
Using Python and Scikit-Learn to analyze blogs in a MySQL database
Downloaded from a jupyter notebook into *.py format
import mysql.connector
import re
import pandas as pd
import numpy as np
# dict to group blogs by keywords
from collections import defaultdict
d = defaultdict(list)
# everything
plot_title = "Non-Terse-Verse Philadelphia Reflections"
query = '''SELECT title, blog_contents, table_key
FROM individual_reflections
WHERE LOWER(title) NOT LIKE '%terse%' AND
LOWER(title) NOT LIKE '%znote%' AND
LOWER(title) NOT LIKE '%front stuff%' '''
def remove_html_tags(text):
"""Remove html tags from a string"""
import re
clean = re.compile('<.*?>')
step1 = re.sub(clean, ' ', text)
step2 = step1.replace('\n', ' ').replace('\r', '')
step3 = ' '.join(step2.split())
text=step3.lower()
text=re.sub("","",text)
text=re.sub("(\\d|\\W)+"," ",text)
text=text.strip()
return text
mydb = mysql.connector.connect(
host="",
user="",
passwd="",
database=''
)
cursor = mydb.cursor()
cursor.execute(query)
df_idf = pd.DataFrame([])
for (title, blog_contents, table_key) in cursor:
blog_contents = remove_html_tags(blog_contents)
title = remove_html_tags(title)
df_idf = df_idf.append(pd.DataFrame({'table_key': table_key, 'title': title, 'body': blog_contents}, index=[0]), ignore_index=True)
df_idf['text'] = df_idf['title'] + " " + df_idf['body']
docs_test = df_idf['text'].tolist()
cursor.close()
mydb.close()
df_idf.head()
from sklearn.feature_extraction.text import CountVectorizer
import re
#get the text column
docs=df_idf['text'].tolist()
#create a vocabulary of words,
#ignore words that appear in 85% of documents,
#eliminate stop words
cv=CountVectorizer(max_df=0.85,stop_words='english',max_features=10000) # cv = cv
word_count_vector=cv.fit_transform(docs) # cv_fit = word_count_vector
list(cv.vocabulary_.keys())[:10]
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer=TfidfTransformer(smooth_idf=True,use_idf=True)
tfidf_transformer.fit(word_count_vector)
def sort_coo(coo_matrix):
tuples = zip(coo_matrix.col, coo_matrix.data)
return sorted(tuples, key=lambda x: (x[1], x[0]), reverse=True)
def extract_topn_from_vector(feature_names, sorted_items, topn=10):
"""get the feature names and tf-idf score of top n items"""
#use only topn items from vector
sorted_items = sorted_items[:topn]
score_vals = []
feature_vals = []
# word index and corresponding tf-idf score
for idx, score in sorted_items:
#keep track of feature name and its corresponding score
score_vals.append(round(score, 3))
feature_vals.append(feature_names[idx])
#create a tuples of feature,score
#results = zip(feature_vals,score_vals)
results= {}
for idx in range(len(feature_vals)):
results[feature_vals[idx]]=score_vals[idx]
return results
# mapping of index
feature_names=cv.get_feature_names()
# human-readable list of keywords for each blog
myfile = open('.../tf-idf.txt', 'w')
# explode-able/split-able list of keywords for each blog
kwfile = open('.../kwds.txt', 'w')
header = '''
==========================================
10 most-significant keywords for each blog
=========================================='''
print(header)
myfile.write(header+"\n")
for i in range(len(docs)):
# get the document that we want to extract keywords from
doc=docs[i]
#generate tf-idf for the given document
tf_idf_vector=tfidf_transformer.transform(cv.transform([doc]))
#sort the tf-idf vectors by descending order of scores
sorted_items=sort_coo(tf_idf_vector.tocoo())
#extract only the top n; n here is 10
keywords=extract_topn_from_vector(feature_names,sorted_items,10)
# now print the results
print("\n=====Title=====")
myfile.write("\n=====Title=====\n")
print(df_idf.iloc[i]['table_key'], df_idf.iloc[i]['title'])
myfile.write("{} {}\n".format(df_idf.iloc[i]['table_key'],df_idf.iloc[i]['title']))
kwds = str(df_idf.iloc[i]['table_key'])+'|'
print("\n===Keywords===")
myfile.write("\n===Keywords===\n")
for k in keywords:
print(k,keywords[k])
d[k].append((df_idf.iloc[i]['table_key'],
keywords[k],
df_idf.iloc[i]['title']))
myfile.write("{} {}\n".format(k,keywords[k]))
kwds += k+','
kwfile.write(kwds[:-1]+"\n")
myfile.close()
kwfile.close()
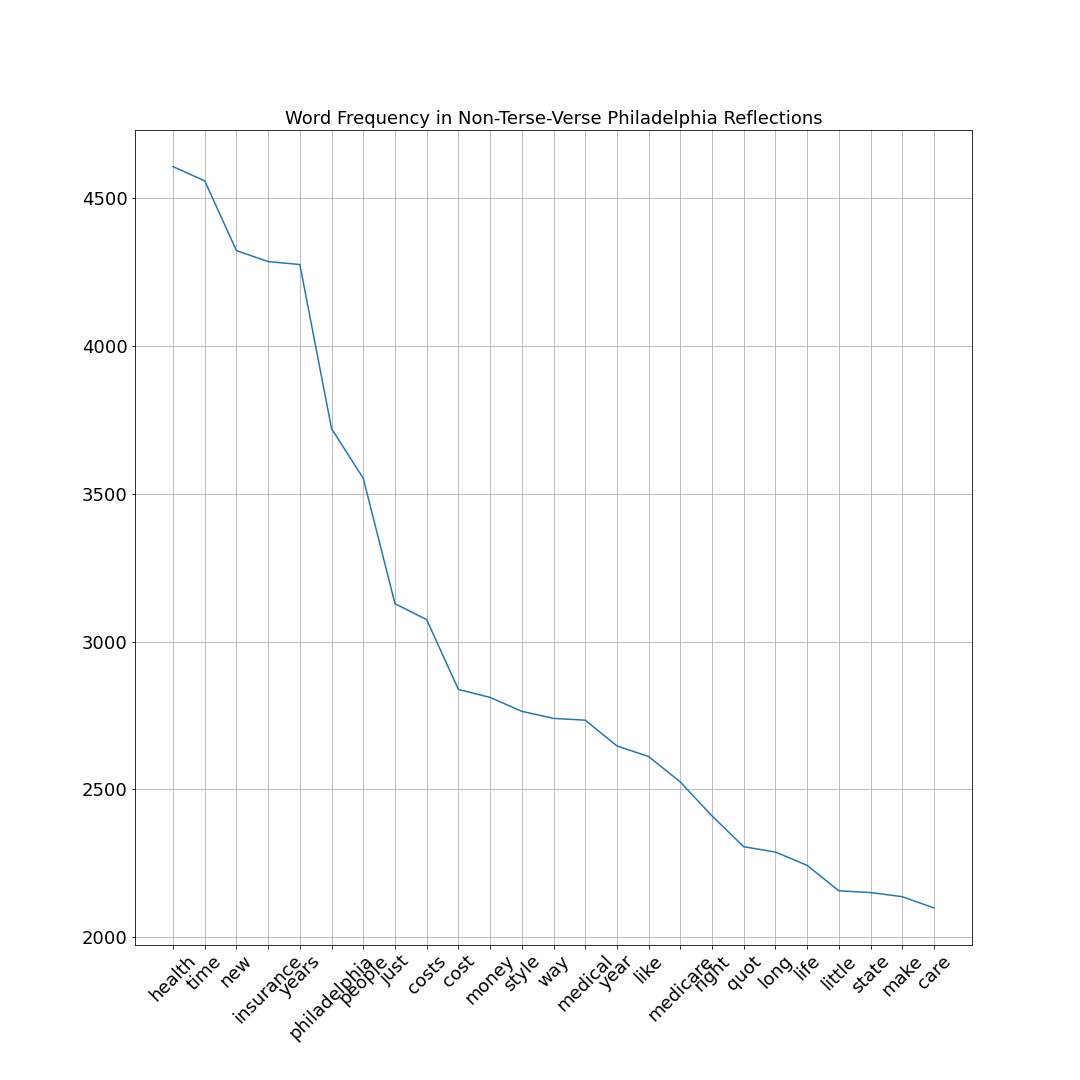
import operator
word_list = cv.get_feature_names();
count_list = word_count_vector.toarray().sum(axis=0)
word_freq = sorted(dict(zip(word_list,count_list)).items(), key=operator.itemgetter(1), reverse=True)
x = []
y = []
for word,freq in word_freq[:25]:
x.append(word)
y.append(freq)
from matplotlib import pyplot as plt
plt.figure(figsize=(15,15))
plt.plot(x,y)
plt.title("Word Frequency in "+plot_title,fontsize=18)
plt.xticks(rotation=45,fontsize=18)
plt.yticks(fontsize=18)
plt.grid()
plt.show()
plt.savefig('.../Word_Frequency.png')
# # Group blogs by keywords
myfile = open('.../Keyword_Popularity.txt', 'w')
header = '''
==================================================
Most-Frequent Keywords with the blogs they specify
==================================================
(blog key, keyword importance, blog title)
..................................................\n'''
print(header)
myfile.write(header+"\n")
x = []
y = []
for k in sorted(d, key=lambda k: len(d[k]), reverse=True):
if len(d[k]) == 1: break
x.append(k)
y.append(len(d[k]))
print(len(d[k]),"blogs contain the keyword","'"+k+"'")
myfile.write("{} blogs contain the keyword '{}'\n".format(len(d[k]), k))
print('---------------------------------------------')
myfile.write("---------------------------------------------\n")
for t in sorted(d[k], key=lambda tup:(-tup[1], tup[2])):
print(t)
myfile.write("{}\n".format(t))
print ('*****\n')
myfile.write('*****\n\n')
myfile.close()
num = 50
plt.figure(figsize=(15,15))
plt.plot(x[:num],y[:num])
plt.title(str(num)+" Most Popular Keywords in "+plot_title,fontsize=18)
plt.xticks(rotation=90,fontsize=12)
plt.yticks(fontsize=18)
plt.ylabel("Number of blogs with this keyword",fontsize=18)
plt.grid()
plt.savefig('.../Keyword_Popularity.png')
plt.show()
Originally published: Monday, October 07, 2019; most-recently modified: Monday, October 07, 2019